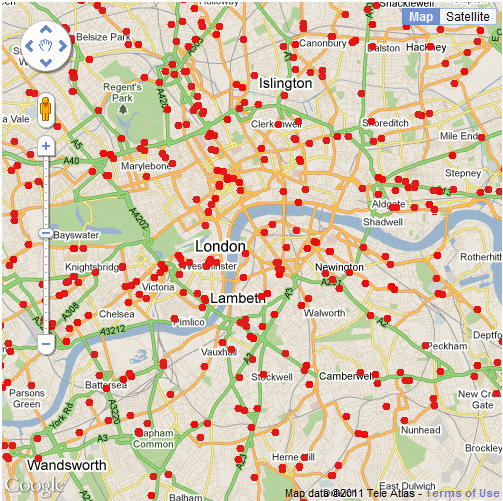
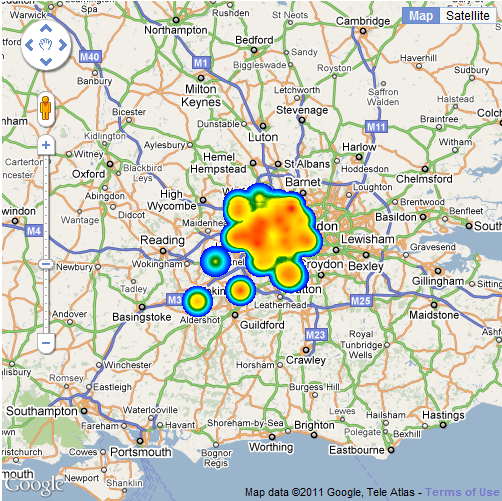
A lot of the maps I have created over the last few years have started out as tabular data in PDF documents. A recent BBC London report contained a dataset obtained from TfL of all the schools in London which are within 150 metres of a road carrying 10,000 vehicles a day or more. The report is a PDF with 21 pages, so editing this manually wasn’t an option and I decided that it was time to look into automatic extraction of tabular data from PDFs. What follows explains how I achieved this, but to start with, here is the final map of the data:
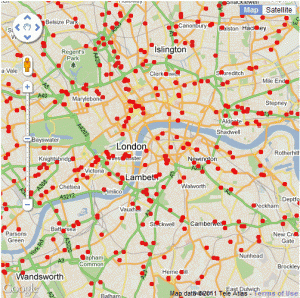
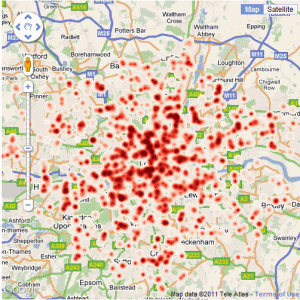
The data for the above map comes from a freedom of information request made to TfL requesting a list London schools near major roads. The request was made by the Clean Air in London group and lists all schools within 150 metres of roads carrying 10,000 vehicles a day or more. The report included a download link to the data, which is in the form of a 21 page PDF table containing the coordinates of the schools:
BBC London Article: http://www.bbc.co.uk/news/uk-england-london-13847843
Download Link to Data: http://downloads.bbc.co.uk/london/pdf/london_schools_air_quality.pdf
The reason that PDFs are hard to handle is that there is no hard structure to the information contained in the document. The PDF language is simply a markup for placing text on a page, and so only contains information about how and where to render characters. The full PDF 1.4 specification can be found at the following link:
http://partners.adobe.com/public/developer/en/pdf/PDFReference.pdf
Extracting the data from this file manually isn’t an option, so I had a look at a library called iTextSharp (http://sourceforge.net/projects/itextsharp/), which is a port of the Java iText library into C#. The Apache PDFBox (http://pdfbox.apache.org/ ) project also looked interesting, but I went with iTextSharp for the first experiment. As the original is in Java, so are all the examples, but it’s not hard to understand how to use it. Fairly quickly, I had the following code:
[csharp]
using System;
using System.Text;
using System.IO;
using iTextSharp.text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFReader
{
class Program
{
static void Main(string[] args)
{
ReadPdfFile("..\\..\\data\\london_schools_air_quality.pdf","london_schools_air_quality.csv");
}
public static void ReadPdfFile(string SrcFilename,string DestFilename)
{
using (StreamWriter writer = new StreamWriter(DestFilename,false,Encoding.UTF8))
{
PdfReader reader = new PdfReader(SrcFilename);
for (int page = 1; page {
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.SimpleTextExtractionStrategy();
//ITextExtractionStrategy its = new CSVTextExtractionStrategy();
string PageCSVText = PdfTextExtractor.GetTextFromPage(reader, page, its);
System.Diagnostics.Debug.WriteLine(PageCSVText);
writer.WriteLine(PageCSVText);
}
reader.Close();
writer.Flush();
writer.Close();
}
}
}
}
[/csharp]
This is one of the iText examples to extract all the text from a PDF and write out a plain text document. The key to extracting the data from the PDF table in the schools air quality document is to write a new class implementing the ITextExtractionStrategy interface to extract the columns and write out lines of data in CSV format.
It should be obvious from the above code that the commented out line is where I have substituted the supplied text extraction strategy class for my own one which I modified to write CSV lines:
[csharp]
ITextExtractionStrategy its = new CSVTextExtractionStrategy();
[/csharp]
The CSVTextExtractionStrategy class is defined in a separate file and is part of my “PDFReader” namespace, not “iTextSharp.text.pdf.parser”.
[csharp]
using System;
using System.Text;
using iTextSharp.text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFReader
{
public class CSVTextExtractionStrategy : ITextExtractionStrategy
{
private Vector lastStart;
private Vector lastEnd;
private StringBuilder result = new StringBuilder(); //used to store the resulting string
public CSVTextExtractionStrategy()
{
}
public void BeginTextBlock()
{
}
public void EndTextBlock()
{
}
public String GetResultantText()
{
return result.ToString();
}
/**
* Captures text using a simplified algorithm for inserting hard returns and spaces
* @param renderInfo render info
*/
public void RenderText(TextRenderInfo renderInfo)
{
bool firstRender = result.Length == 0;
bool hardReturn = false;
LineSegment segment = renderInfo.GetBaseline();
Vector start = segment.GetStartPoint();
Vector end = segment.GetEndPoint();
if (!firstRender)
{
Vector x0 = start;
Vector x1 = lastStart;
Vector x2 = lastEnd;
// see http://mathworld.wolfram.com/Point-LineDistance2-Dimensional.html
float dist = (x2.Subtract(x1)).Cross((x1.Subtract(x0))).LengthSquared / x2.Subtract(x1).LengthSquared;
float sameLineThreshold = 1f; // we should probably base this on the current font metrics, but 1 pt seems to be sufficient for the time being
if (dist > sameLineThreshold)
hardReturn = true;
// Note: Technically, we should check both the start and end positions, in case the angle of the text changed without any displacement
// but this sort of thing probably doesn’t happen much in reality, so we’ll leave it alone for now
}
if (hardReturn)
{
//System.out.Println("<< Hard Return >>");
result.Append(Environment.NewLine);
}
else if (!firstRender)
{
if (result[result.Length – 1] != ‘ ‘ && renderInfo.GetText().Length > 0 && renderInfo.GetText()[0] != ‘ ‘)
{ // we only insert a blank space if the trailing character of the previous string wasn’t a space, and the leading character of the current string isn’t a space
float spacing = lastEnd.Subtract(start).Length;
if (spacing > renderInfo.GetSingleSpaceWidth() / 2f)
{
result.Append(‘,’);
//System.out.Println("Inserting implied space before ‘" + renderInfo.GetText() + "’");
}
}
}
else
{
//System.out.Println("Displaying first string of content ‘" + text + "’ :: x1 = " + x1);
}
//System.out.Println("[" + renderInfo.GetStartPoint() + "]->[" + renderInfo.GetEndPoint() + "] " + renderInfo.GetText());
//strings can be rendered in contiguous bits, so check last character for " and remove it if we need
//to stick two rendered strings together to form one string in the output
if ((!firstRender)&&(result[result.Length – 1] == ‘\"’))
{
result.Remove(result.Length – 1, 1);
result.Append(renderInfo.GetText() + "\"");
}
else
{
result.Append("\"" + renderInfo.GetText() + "\"");
}
lastStart = start;
lastEnd = end;
}
public void RenderImage(ImageRenderInfo renderInfo)
{
}
}
}
[/csharp]
As you can probably see, this file is based on “iTextSharp.text.pdf.parser.SimpleTextExtractionStrategy”, but inserts commas between blocks of text that have gaps between them. It might seem like a better idea to parse the structure of the PDF document and write out blocks of text as they are discovered, but this doesn’t work. The London schools air quality example had numerous instances where text in one of the cells (e.g. a school name, Northing or Easting) was split across two text blocks in the pdf file. The only solution is to implement a PDF renderer and extract text using its positioning on the page to separate columns.
The result of running this program on the London schools air quality PDF is a nicely formatted CSV file which took about 5 minutes to edit into a format that I could make the map from. All I had to do was remove the page number and title lines from between the pages and add a header line to label the columns. There were also a couple of mistakes in the original PDF where the easting and northing had slipped a column.