This is starting to become obsessive, but I can’t help wondering how many trains are running on the London Underground and where they all are. The Trackernet web service released by TfL allows you to see all the running boards for stations on a line, but doesn’t tell you where all the trains are. I did an earlier post about just the Victoria line trains, but I’ve now built this into a web service that works out locations for trains on the whole network.
![]()
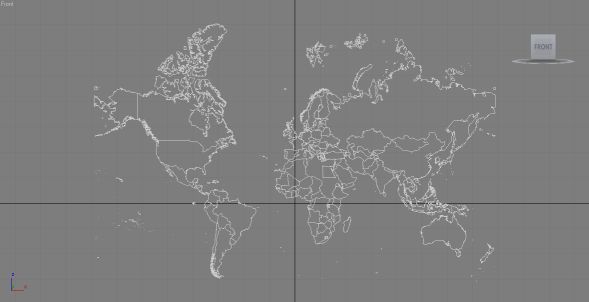
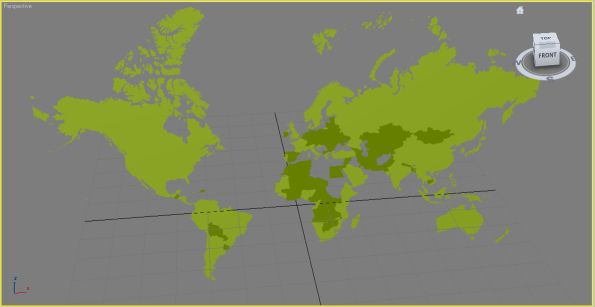
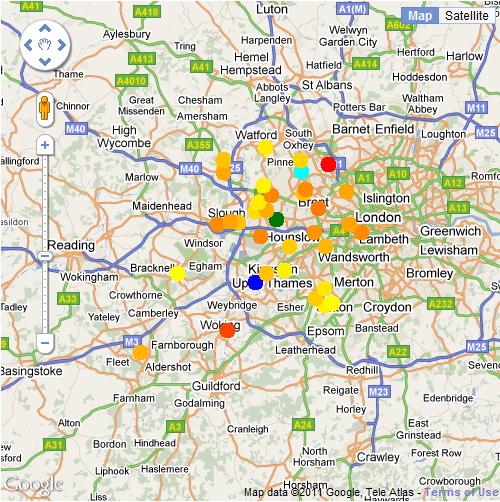
Trains on the London Underground network for 11:30am on 30th November 2011
The map colours follow the normal line colours, so District (Green), Victoria (Light Blue), Central (Red), Northern (Black), Bakerloo (Brown), Jubilee (Grey), Piccadilly (Dark Blue), Waterloo and City (light green). Note that Circle and Hammersmith and City are all shown as yellow and there are no pink markers on the map. This is because the Trackernet API does not distinguish between Circle and Hammersmith and City trains and both lines are queried in one web request, so they’re difficult to separate out.
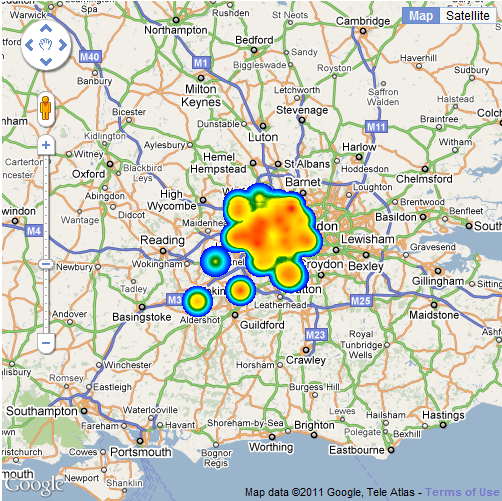
The idea is to build this into a web service and publish it on MapTube as a real-time Tube map. Using the locations of trains and the time to station information we can build a model of whether a line is running normally and where delays are occurring.
The basic technique behind how the positions are calculated relies on using the time to station information from the running boards at every station on the route to find the minimum time for every unique train. This is then taken as the most accurate location estimate and its position interpolated between the last and next stations based on the time. It is actually a lot harder to work out which line a train is on due to the fact that multiple lines can share platforms at the same station. For example, query the Piccadilly line and the District line and the resulting data will contain Barons Court for both, so you have to separate out the Piccadilly trains and the District trains and make sure you don’t count the same ones twice.
Now that the code can handle the Underground network, the next steps are to do the same for National Rail, London Buses and London River Services.
If you’re interested in live train data, it’s also worth looking at the following site that was created by Matthew Somerville: http://traintimes.org.uk/map/tube