Version 1.42 of the Image Cutter software was released yesterday. This includes the addition of a template to allow the use of Google’s API v3. This version of the Google Maps API doesn’t require an API key and works better than v2 does on mobile devices like iPhones, iPads and Android tablets.
You can download the latest version at the following link: Image Cutter 1.42
This is starting to become obsessive, but I can’t help wondering how many trains are running on the London Underground and where they all are. The Trackernet web service released by TfL allows you to see all the running boards for stations on a line, but doesn’t tell you where all the trains are. I did an earlier post about just the Victoria line trains, but I’ve now built this into a web service that works out locations for trains on the whole network.
Trains on the London Underground network for 11:30am on 30th November 2011
The map colours follow the normal line colours, so District (Green), Victoria (Light Blue), Central (Red), Northern (Black), Bakerloo (Brown), Jubilee (Grey), Piccadilly (Dark Blue), Waterloo and City (light green). Note that Circle and Hammersmith and City are all shown as yellow and there are no pink markers on the map. This is because the Trackernet API does not distinguish between Circle and Hammersmith and City trains and both lines are queried in one web request, so they’re difficult to separate out.
The idea is to build this into a web service and publish it on MapTube as a real-time Tube map. Using the locations of trains and the time to station information we can build a model of whether a line is running normally and where delays are occurring.
The basic technique behind how the positions are calculated relies on using the time to station information from the running boards at every station on the route to find the minimum time for every unique train. This is then taken as the most accurate location estimate and its position interpolated between the last and next stations based on the time. It is actually a lot harder to work out which line a train is on due to the fact that multiple lines can share platforms at the same station. For example, query the Piccadilly line and the District line and the resulting data will contain Barons Court for both, so you have to separate out the Piccadilly trains and the District trains and make sure you don’t count the same ones twice.
Now that the code can handle the Underground network, the next steps are to do the same for National Rail, London Buses and London River Services.
If you’re interested in live train data, it’s also worth looking at the following site that was created by Matthew Somerville: http://traintimes.org.uk/map/tube
I’ve been meaning to look at TfL’s Trackernet API for a while now. It works through a REST based web service which gives access to all the London Underground running boards on a line by line basis. You issue an http request of the form:
and the result is an XML file containing train information for every station on the Victoria Line. Substitute “B” instead of “V” and you get the Bakerloo line instead. I had managed to figure out a way to get approximate train locations when the Victoria Line got suspended one morning, so I couldn’t resist looking to see where all the trains had ended up:
According to my data, there are 25 trains on the line. The way the positions are calculated is quite complicated as the original information comes from the running boards for every station and the time to platform estimates. Trains are uniquely identified through a train number and a set number as a composite key. I simply iterate through all the data for every station and take the lowest time to station for every train, which gives me the train’s next station. Then I use the location code provided by the API and the time to station estimate to interpolate between the last station and the next station.
One feature worth noting is that because the time to station is given for every station along the train’s whole route, you can use the data to build up a dataset of the time required to travel between any pair of stations. Also, because the information is processed from the running boards, the program should be able to process National Rail train locations from the information on their website.
By using only the information provided in the XML response from the API means that I am able to construct a web service that doesn’t require any state information to be retained between calls. In addition to this, it doesn’t require any knowledge of the tube network and how the stations are connected together.
This is still very much a prototype, but once it’s working for all the lines, it will be released as a real-time feed on MapTube.
Recently, BBC Look East have been running a “Broadband Speed Survey”, asking people to use an online tester to check their broadband speed, and then enter the value, along with their postcode, into SurveyMapper. This generated 16,311 responses to the survey, but for each response people get to view the map containing the latest data, so the tile server drawing the data on the map gets about 100 times as many hits.
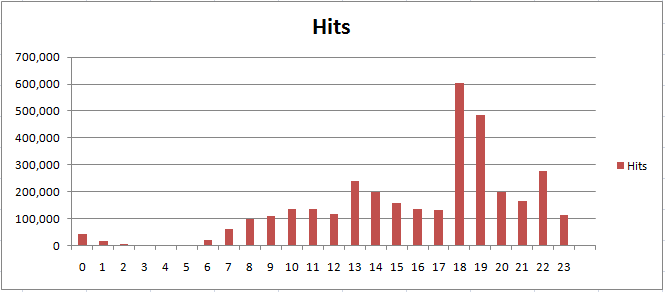
When the survey was advertised on the 18:30 news bulletin on the Tuesday that week, we started to get a huge number of hits in a very short space of time. The following graph shows the hits by hour of day for all five days that week.
The peaks tie in quite well with the 18:30 and 22:30 news bulletins, but it can be seen from the statistics that the tile server took over a million hits in the space of a couple of hours. The tile server itself is a single machine running Server 2008 R2 Core, virtualised with two processors assigned. Once it became apparent how many hits we were getting, this was increased to 4 processors and 4GB of RAM. This shows the main benefit of virtualisation for us, which is that we could shutdown non-operational machines used purely for research and divert the computing power to the operational web servers which were taking the high loads. In order for the maps on SurveyMapper to work, we are also dependent on a database server and the dedicated web server which runs the MapTube and SurveyMapper sites, in additional to the tile server. What’s interesting about this experience is that it taught us that the database server is capable of handling a much higher load than this.
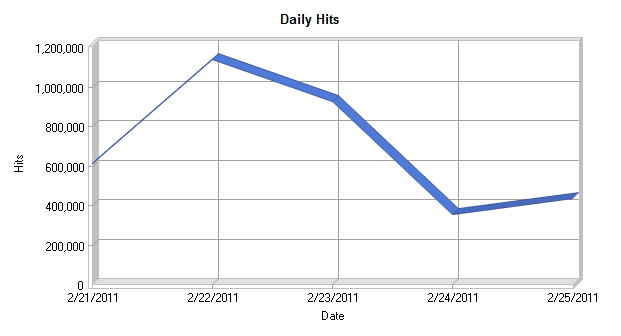
From the graph of the daily hits, it can be seen that most of the traffic was on Tuesday 22nd February, which is the first day it was advertised on the news. After this it tails off as the week progresses. One other interesting thing that was noticed when analysing the log files is the browser and operating system statistics.
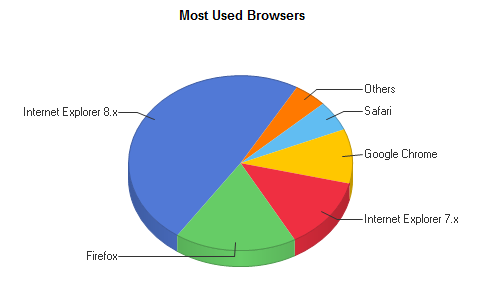
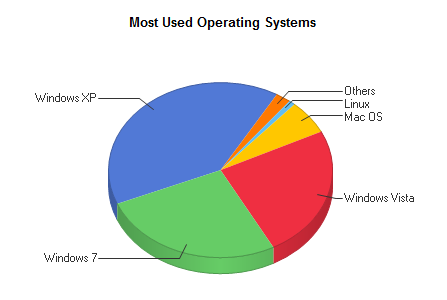
Browsers used to access SurveyMapper
Operating Systems
So, from these statistics, it’s a three way split between Windows XP, Vista and 7, with IE8 the most popular browser. Chrome, Firefox and Safari are lagging behind, which is surprising bearing in mind the profileration of Macs.
Now that we’ve proved a single element IIS7.5 server can take a million hits, we’re looking into the possibility of creating multiple tile servers dsitributed across two virtualisation servers and load balancing.
We’ve just updated the MapTube website with a new release of the software that makes all of the Census maps clickable. Anything tagged with the “CENSUS2001″ keyword is clickable, as well as most of the maps made from the data on the London DataStore.
The new clickable map icon. This is used to turn the clickable maps feature on or off.
The resulting popup window showing attribute data for the feature that has been clicked.
The maps page now contains an additional button below the zoom level slider which shows a representation of a mouse. If this is enabled, as shown below, then a single mouse click on the map will display a popup window containing more information about the feature just as in a traditional GIS.
The image on the right shows the default popup window which just lists the attributes from the CSV file used to make the map. If you want to examine the data, there is a link to download the CSV file from the ‘more information’ page.
The html in the popup window is obtained by applying a transformation to the attribute data that turns it into the html that you see displayed in the window. In the next release of MapTube we will include a user interface to allow people to build maps of fixed geometry data (i.e. census data, ward codes, districts, countries etc) directly from data in a CSV file. We are also planning to add a web based interface to allow people to write what appears in the popup window themselves so that it will be possible to include graphs and charts.
Using the General Election 2010 results spreadsheet from the Guardian Data Blog, we’ve produced three MapTube maps showing the distribution of votes for the three main parties:
The maps can be viewed on MapTube at the following link:
While playing around with 3DS Max 2009 for some of our GENeSIS work, I happened to notice that it’s now possible to use .net assemblies in MaxScript. My first thought was to use this for some of our agent based modelling work, but when Fabian Neuhaus asked about importing GPX files, I saw a really easy way of doing this.
The “System.Xml” assembly in .net makes parsing the GPX file extremely simple. A GPX file is nothing more than an xml file containing a list of trackpoints with a lat/lon and a time. The following script parses a GPX file and generates an animation of a box following a spline which follows the GPS track:
In order to use this, you have to run the script from the MaxScript rollout on the Utilities menu (click the hammer on the right hand side). Then click the “MaxScript” and “Run Script”. Point the file dialog to the file dowloaded from above and it should run.
The script creates a rollout window which allows you to browse for a GPX file to upload. After this is done, the file will be imported, resulting in an “Import Successful” message.
The only problems you might get are to do with the format of time recorded by the GPS in the track. If the import refuses to work, then you might need to change the time format as indicated by the comments in the MaxScript file.
One other thing worth mentioning is that the lat and long coordinates have been multiplied by 1000 in order to cope with a lack of granularity in Max. After producing this version of the script which loads data in the WGS84 coordinate system, I then created another version which reprojects the data into the OSGB36 system that Ordnance Survey uses in the UK. This means that we can match up the GPS tracks in Max with our own data on building footprints which comes from Ordnance Survey.
For movies showing the animated GPX tracks, have a look at the Urban Tick website:
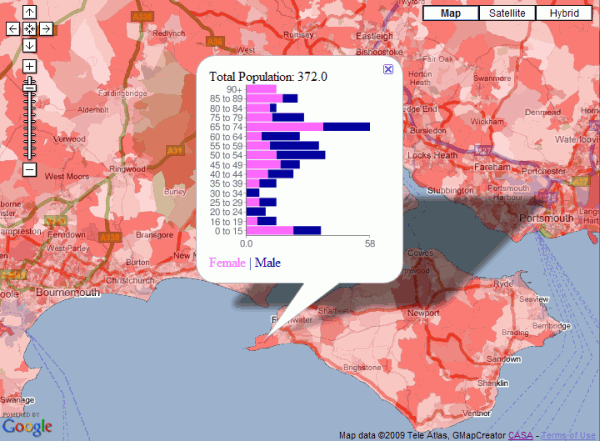
It’s actually a stacked bar chart rather than a traditional population pyramid, but the image below shows male/female population by age for all the output areas in England. The red thematic overlay is total population for every OA, which can be clicked to get the age group breakdown shown in the popup window.
Clickable Age Map
This map is a variation on the original clickable OAC map and was built using a new version of the GMapCreator which contains the clickable technology. Traditionally, maps like this have been built using a server and database to translate the click on the client into a geographic area using point in polygon and then sending the query data back to the client. This method doesn’t scale when you have limited server resources and are looking to handle high numbers of hits, for example with the Mood Maps that we’ve been doing recently. An alternative solution is to build feature coded tiles and let the client handle most of the work displaying the data. Using this system, there is a second set of tiles, one of which the client downloads when the user clicks on a point. This allows the client to work out which feature has been clicked and request the data for that area as an xml file.
The hard part is designing a system which can allow people to design the popup window without having to resort to programming. In the example above, the graph was created using Google Charts via the GMapCreator’s user interface. All that was needed was to choose the data fields from a list and to select the chart type. The URI string to create the chart comes from an xslt transform applied to the xml data. This transform is automatically created by the GMapCreator interface, which also allows the rest of the popup window to be designed using a simple html editor.
This is one of those things that’s obvious once you know it, but I’ve often found myself developing code for tiled maps, but without a connection to the Internet. Often, I just want a quick check to see if the tiles are rendered correctly, so I don’t need the background map.
The obvious solution is to create an OpenLayers page with your custom tiles as the base layer. The javascript that makes OpenLayers work can be served locally, unlike the Google API, so by only having one layer of locally served tiles, you don’t need an Internet connection.
The html pattern follows the OpenLayers ‘howto’ guide and uses a custom TMS layer as follows:
var googlecustom=new OpenLayers.Layer.TMS(“Test”,http://www.casa.ucl.ac.uk/googlemaps/,{ ‘type’: ‘png’, ‘isBaseLayer’: true, ‘getURL’: TMSCustomGetTileURL });
The ‘TMSCustomGetTileURL’ returns the tile url based on the x, y and z value in whatever format you are storing tiles in. For this project, it was the keyhole string format.
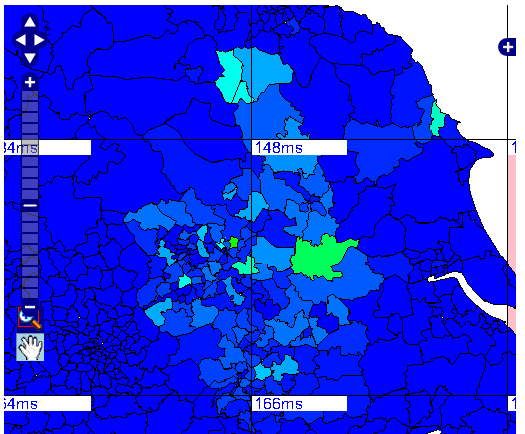
OpenLayers map showing data from the BBC Look North Recession mood map using dynamic tile creation
The image above was taken from a prototype system using C# and SQL Server 2008 to generate tiles dynamically from data stored in a CSV file at a URL.
MapTube was 1 year old last week and to celebrate we have released an addition which allows you to change the background map to OpenLayers and OpenStreetMap.
Google and OpenLayers Toggle
The blue ‘G’ and the greyed out OpenLayers icon toggle the API between Google and OpenLayers. On the OpenLayers view, the basemaps can be the Mapnik, Osmarender or the Cycle Map layers which are all based on OpenStreetMap data. In addition to this, the OpenLayers API can also use the standard Google tiles as the basemap.
When creating a link to a map, the API currently in use is encoded into the URL when the ‘link to this map’ option is used. This shows up in the URL’s parameter list as “m=ol” for OpenLayers or “m=gm” for Google. For organisations where publishing links to Google Maps is a problem, this provides an open source alternative.